

How Retrieval-Augmented Generation is evolving into Self-RAG and Agentic RAG Systems
Retrieval-Augmented Generation (RAG) has become one of the most widely used techniques in enterprise AI systems. It combines large language models with external knowledge sources, enabling more grounded and context-aware outputs. For many applications, especially those involving static documents or FAQs, RAG offers a clear improvement over zero-shot prompting or fine-tuning alone.
But as use cases grow more complex, RAG begins to show its limits.
Traditional RAG retrieves a handful of documents and generates an answer in a single step. It does not reflect on what it retrieves, cannot plan its retrieval path, and has no way of knowing whether the final answer is well supported. In tasks where precision matters, or where queries evolve across multiple steps, this approach falls short.
That is where Self-RAG and Agentic RAG come in.
This article explores how RAG is evolving to meet the demands of more complex systems. We will unpack what makes Self-RAG more precise, why Agentic RAG offers greater flexibility, and how both are already shaping AI architectures in the real world. Expect a deep dive with practical insights and architectural reasoning throughout.
What is standard RAG and why it falls short
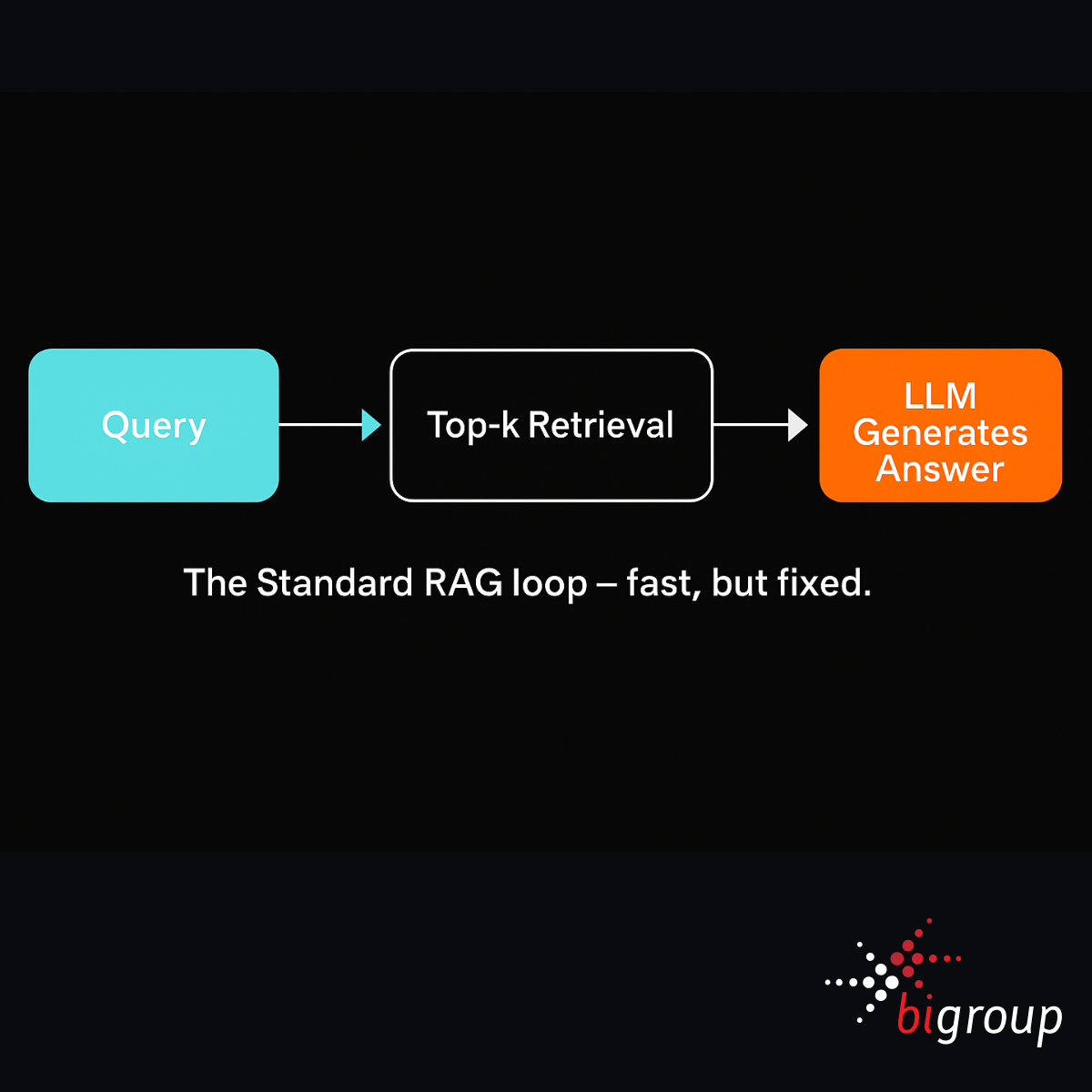
Standard Retrieval-Augmented Generation (RAG) follows a simple loop. A user enters a query, the system retrieves the top-k documents from a knowledge base, and a language model generates a response based on that information. This method offers a lightweight way to inject external knowledge into LLM outputs without full retraining.
In many cases, this works well. For tasks like summarising policies, answering FAQs, or searching internal wikis, Standard RAG is fast, effective, and easy to implement. It is one of the reasons it has become a default pattern in enterprise AI applications.
But the simplicity that makes Standard RAG attractive is also what limits it.
It treats every query as a one-shot operation. There is no feedback loop, no reflection on whether the retrieved documents are actually relevant, and no refinement of the query. If the initial results are off-target, the answer will be too. This makes it brittle in situations where nuance, context, or layered reasoning is required.
You can think of it like doing a single Google search and immediately writing a report based only on the top few links. If the results are poor or incomplete, the output will be as well.
For complex or high-stakes use cases, this approach is often not enough. It provides speed but not depth, and leaves no room for improvement once the generation has started.
Self-RAG: precision through iterative self-correction
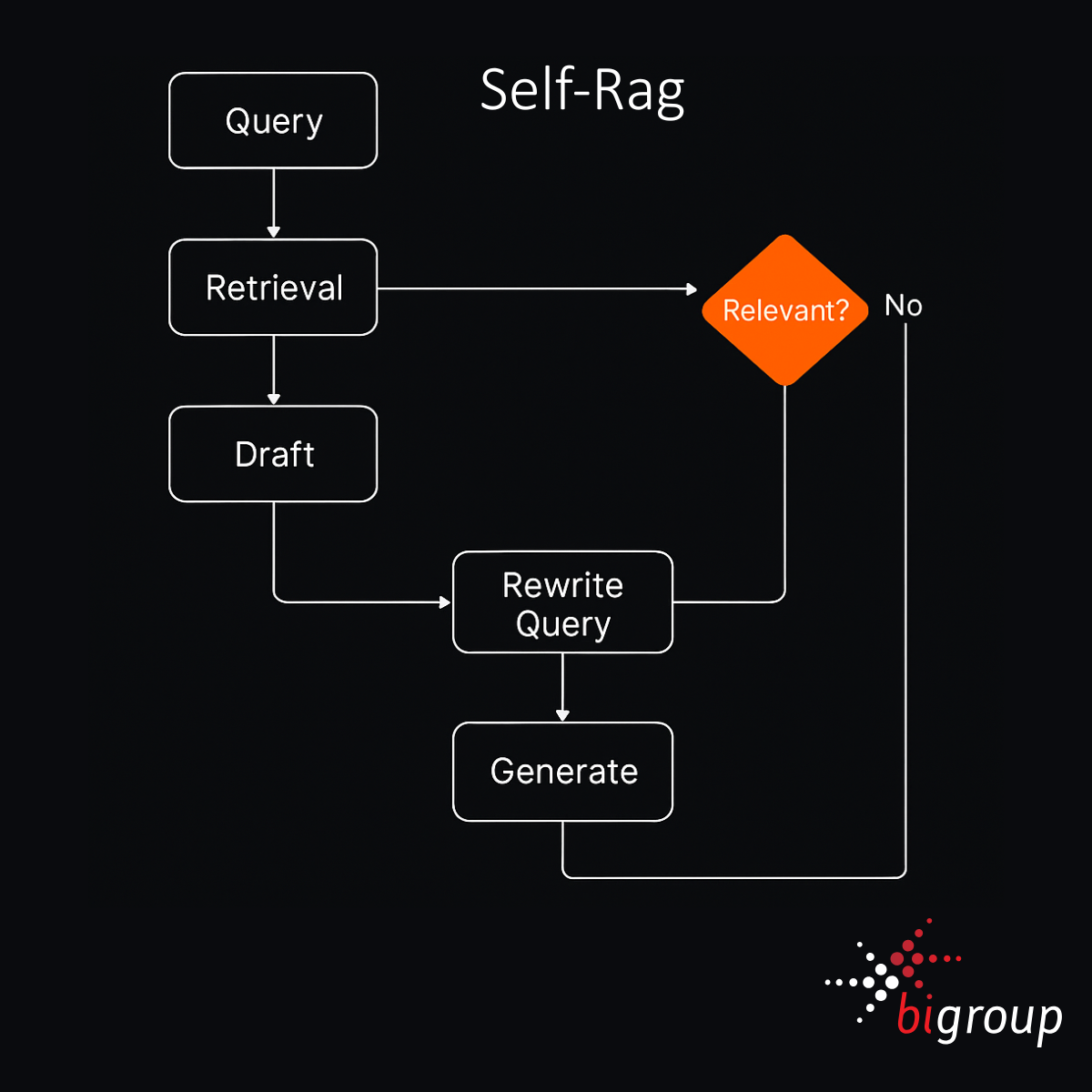
Self-RAG builds on the basic RAG pipeline by adding a feedback loop. Instead of generating an answer immediately after retrieval, it pauses to evaluate whether the retrieved content is good enough to support a reliable response. If not, it rewrites the query, retrieves again, and only then generates a revised answer.
The loop looks like this:
Retrieve → Draft → Reflect → Rewrite Query → Retrieve Again → Generate Improved Answer
This structure draws inspiration from chain-of-thought reasoning and verification loops often found in academic research. The model is no longer passively consuming retrieved documents but actively checking the quality of its own process.
Self-RAG is particularly well suited to tasks that require strong factual grounding or regulated outputs. Legal analysis, policy validation, and complex document verification all benefit from the added step of reflection. Instead of hallucinating around gaps in the retrieved data, the model is pushed to interrogate its sources more carefully.
That said, there are trade-offs. Self-RAG is slower and more resource-intensive. It typically requires more tokens, more iterations, and more sophisticated orchestration. As a result, it is rarely found in off-the-shelf toolkits or enterprise deployments. Most existing implementations are either research prototypes or highly customised solutions.
Still, its potential is clear. In domains where accuracy is more important than speed, and where the cost of getting it wrong is high, Self-RAG offers a level of control and reliability that standard pipelines cannot match.
Agentic RAG – the architecture of autonomy
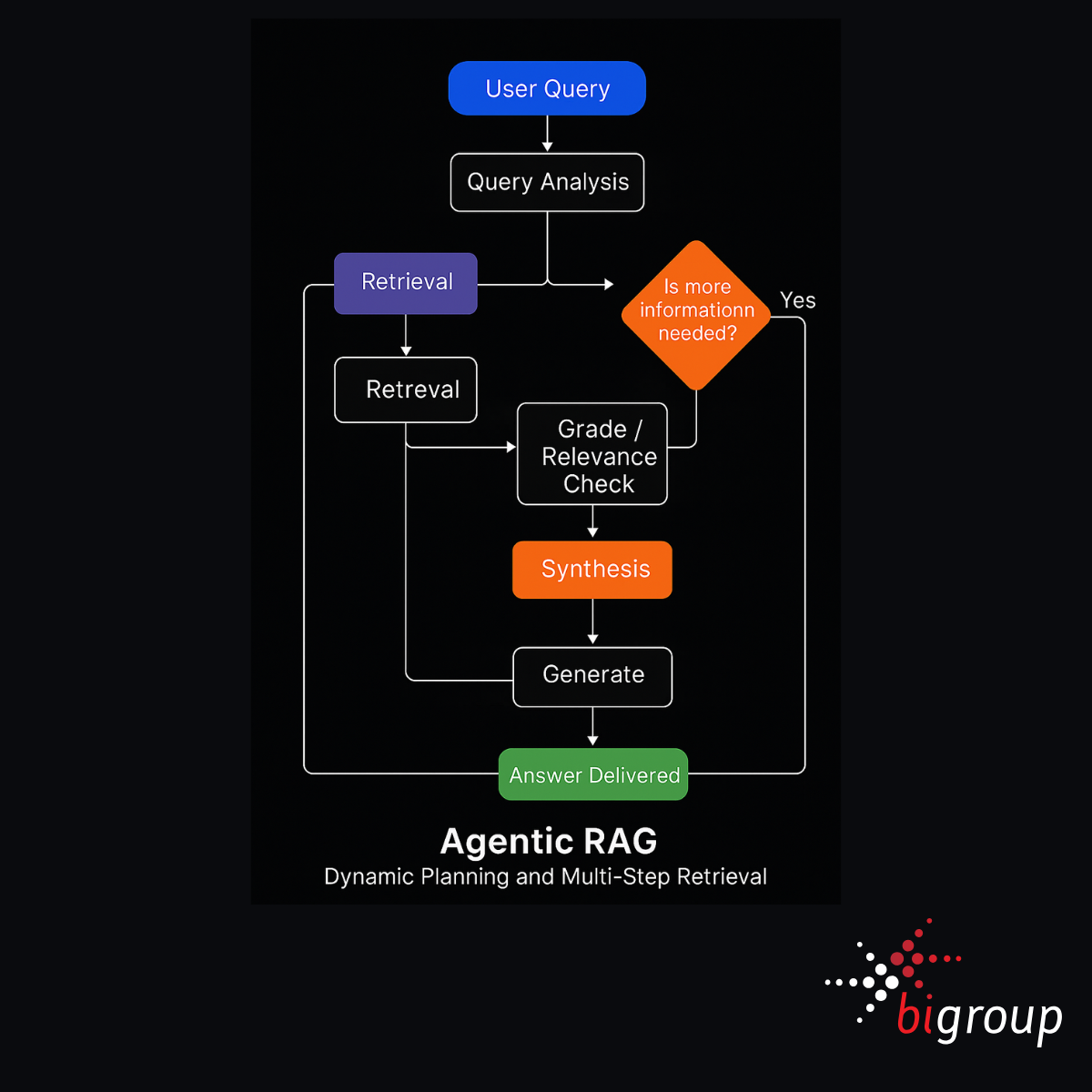
Agentic RAG takes the concept of retrieval-augmented generation further by treating the system not as a one-shot question-answering tool, but as an agent capable of reasoning, planning, and adapting in real time.
At its core, Agentic RAG involves query decomposition, recursive retrieval, iterative refinement, and multi-step synthesis. The system may break down a broad user query into smaller sub-tasks, plan a sequence of retrieval actions, perform intermediate checks, and synthesise the results into a coherent response.
This approach is supported by emerging frameworks such as ReAct, CrewAI, and LangChain agents, which enable modular agent planning and coordination. These frameworks allow the model to choose when to search, when to think, when to ask a clarifying question, and when to deliver a final answer.
What makes Agentic RAG powerful is its flexibility. It excels in situations where a single retrieval step is insufficient, such as:
- navigating ambiguous queries,
- reasoning over incomplete or distributed data,
- or performing multi-hop tasks that require bridging multiple sources of knowledge.
It is also more common in the real world than Self-RAG. You will find Agentic RAG patterns embedded in AI copilots, knowledge workers, research assistants, and automated workflow builders. These systems benefit from dynamic reasoning, the ability to make decisions mid-process, and modular retrieval across varying data sources.
But power comes with complexity.
If not carefully scoped, Agentic RAG can become resource-intensive, expensive to run, and prone to hallucination. Without clear orchestration, version control, or guardrails, these agents may pursue irrelevant paths or synthesise answers from weak sources.
That is why responsible deployment matters. Designing with Agentic RAG means thinking like a systems architect, not just a prompt engineer. It requires a control layer to manage decision points, ensure data grounding, and align outputs with real-world constraints.
Side-by-side comparison – when to use what
Choosing between Standard RAG, Self-RAG, and Agentic RAG is not about picking the most advanced option. It is about selecting the right architecture for the task at hand. Each comes with trade-offs across accuracy, flexibility, runtime, and complexity.
The table below summarises the key differences:
| Feature | Standard RAG | Self-RAG | Agentic RAG |
|---|---|---|---|
| Accuracy | Moderate | High | Varies (can be high) |
| Flexibility | Low | Low | High |
| Runtime | Fast | Slower | Variable |
| Complexity | Low | Medium | High |
| Hallucination Risk | Medium | Low | High (if poorly managed) |
| Tooling Support | Strong (LangChain, Haystack) | Limited (research only) | Growing (LangChain, CrewAI) |
Typical use cases:
- Standard RAG: quick document lookups, internal search, FAQs
- Self-RAG: compliance checks, policy analysis, regulated content
- Agentic RAG: exploratory research, dynamic planning, multi-step workflows
No single method is best in all cases. Simpler pipelines can still outperform complex ones when the task is straightforward. What matters is matching the architecture to the reliability, speed, and interpretability your use case demands.
Real world architecture patterns
The evolution from Standard RAG to Self-RAG and Agentic RAG is not confined to research papers. These architectures are now shaping real-world systems across industries, particularly in enterprise AI, legal tech, and automated research platforms.
In production environments, we often see hybrid architectures that combine retrieval, reasoning, and adaptation in more nuanced ways. For example, a common pattern involves starting with a Standard RAG backbone, then layering fine-tuned LoRA adapters for domain-specific context. This approach reduces cost while increasing the model’s relevance in sectors such as finance, healthcare, or insurance.
Self-RAG is being piloted in use cases where accuracy is paramount. Claim validation tools in insurance, policy consistency checks in public sector audits, and high-risk financial reporting pipelines are already incorporating Self-RAG loops. These implementations often use lightweight internal frameworks or highly customised LangChain flows, with runtime checkpoints for query rewriting and document re-ranking.
Agentic RAG is where we see the most architectural experimentation. In dynamic report generation, for instance, agentic systems decompose user queries into sub-tasks, execute multi-step retrievals across diverse data sources, and synthesise structured outputs. These workflows often involve OpenAI’s Agent SDK, CrewAI, or LangChain agent planners, integrated with LlamaIndex or vector databases like Weaviate and Pinecone.
This shift demands a new mindset. Implementing Agentic or Self-RAG requires orchestration, not just retrieval. Teams must think in loops, plans, and checkpoints, not just top-k search.
RAG in practice, not in theory
Choosing between Standard RAG, Self-RAG, and Agentic RAG is not a one-time decision. It is a strategic choice that should evolve with the complexity, risk, and precision your systems demand. There is no universal winner. What matters is matching the architecture to the problem, with clear boundaries around performance, explainability, and control.
As AI systems become more autonomous, orchestration becomes critical. Retrieval loops are no longer passive. They must be designed, monitored, and governed with the same care as any production system. That includes versioning, auditability, test coverage, and escalation paths.
The future of RAG is not static. It is adaptive, reflective, and accountable.
At BI Group, we work with organisations ready to move beyond plug-and-play models and build AI systems that are trustworthy by design. If you are navigating the architecture decisions behind agentic AI, get in touch, or explore our Responsible AI Blueprint to start building with confidence.